Preface
In this era of ChatGPT, AI has become one of the most widely discussed topics of our time, and it's not hard to see why. With its ability to understand natural language and generate human-like responses, ChatGPT has captured the imagination of many people, including those in the business world. Nowadays, nearly all companies are looking into the implications of ChatGPT and other AI technologies for their own businesses.
Apart from looking for use cases to implement, companies are also trying to understand how precisely an integration of ChatGPT (or any other large language model) could look like. This is more difficult than you might first imagine - we’ll cover that in this booklet.
Before we do this, though, we want to cover a few topics that explain why ChatGPT deserves the attention it currently receives.
Chat interfaces are not a new idea. In fact, one of the first chatbots, “Eliza” (a mock Rogerian psychotherapist) was developed in the 70s.
More prominent examples include personal assistants like Siri or Cortana. Still, these chatbots/assistants never really took off, as their cognitive capacity was highly limited.
So why is it different this time? Why now? The answer lies in the representation of unstructured data.
Let’s take a quick look at how computers process data. Generally, computers are great for tasks such as computing sums of arbitrarily large numbers, as they can be displayed as bits. If you instruct a computer to compute 127 + 4 (e.g. in your calculator), internally it computes the following (don’t read this as a decimal number):
11111110+00100000=11000001
This is a sequence of power of twos: the first 1 represents 20, the second 1 represents 21, and so on. This is called a bitstring. The actual number of a bitstring is the sum of all positions. To sum two bitstrings, you simply go through each index, and sum their respective values; what might feel odd at first is that the highest number in a bitstring is 1, i.e. if you add 1 + 1, the result is not 2, but instead you shift the bit by one index. So if you want to compute 10 + 10, then the result is 01. And this makes sense, as 20 = 1, and 10+10=20+20=1+1=2, which is exactly 21.
No worries if that seems a bit complicated, it just demonstrates that it is easy for a computer to calculate a sum for given numbers.
Now, for textual data, this becomes orders of magnitude more complicated. How can you turn a sentence like “This movie is amazing” into a bitstring? Theoretically, you could try applying some structural logic to convert characters into bitstrings, but the meaning of a sentence is not represented by the number of e.g. “e”s there are in a sentence.
Luckily, AI researchers made significant progress in this question, which leads us to today. The foundation for ChatGPT and other AI models lies in the ability to represent even the most unstructured data (such as complex sentences) into a well-structured data format: vectors.
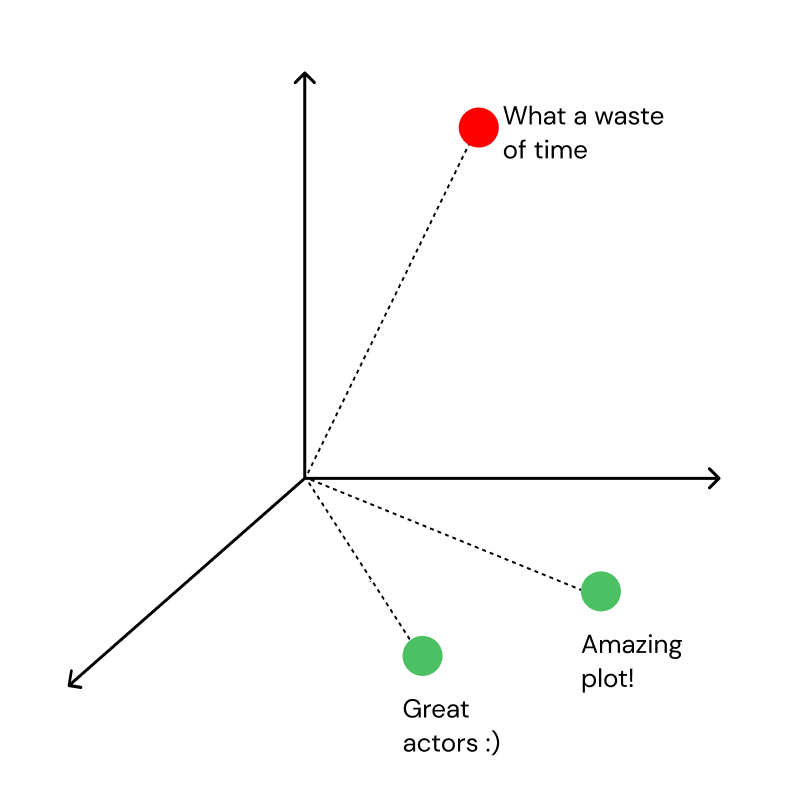
These vectors (also called “embeddings”) are created via so-called encoders, which are models trained on vast amounts of images or textual data. As the general availability of internet-scale data and cloud computing has grown exponentially in the last decade, these encoders became significantly more powerful and can understand e.g. context in a given sentence. In other terms, these models can put similar sentences in meaning close to one another in vector space. Even though this sounds like a neat technical detail, it changes everything. We’ll dive into ways to leverage this capability in later sections.
So we covered the “why now?”. Next: “why is this so relevant?”. That is a simple one. If we’re capable of teaching computers to understand human language, then we’re leveraging one of the key capabilities of humankind.
We use human language to communicate, learn, formulate, reason, etc. This very book is mostly human language and a few images.

What does this mean for businesses? Well, businesses are - at least for now - only possible if humans are working in them. If they communicate with each other (e.g. sales, services, marketing), if they formulate (e.g. HR, legal), if they research (e.g. product teams); the list goes on. As so many of these things require human language in some way, it becomes obvious that the famous sentence “80% of company data is unstructured” makes sense. It’s PDFs, emails, websites, and more. Because we tend to produce data in natural ways, which is human language. Some of this data is contextualized. For instance, text in an invoice can have an implicit meaning if it is written in the top left corner.
With large language models like ChatGPT, we’re now seeing a trend that uncovers these difficult data modalities: foundation models that are capable of representing unstructured data we couldn’t explain well to computers before. We’ll uncover the reason for their naming in the technical best practices section.
ChatGPT became famous because of its uncanny user interface: a simple chat, that seems to finally enable the level of intelligence we hoped for in a chatbot (Eliza, Siri, Cortana, …). Though there are several use cases for a conversational interface, we’ll also cover the power of foundation models as APIs, which are especially helpful in integrated processes.
What’s for sure is that ChatGPT shows the beginning of a new cycle of AI models, and new use cases. With this booklet, we aim to give you the material you need to gain a much better understanding for yourself and your company.
We’re going to cover the topic from two perspectives: consumers of AI, and producers of AI:
- consumer: you want to integrate AI into your process, e.g. for customer services. You might be a process owner or a domain expert in your field. You see the potential of AI for your tasks, but don’t want to build the AI yourself.
- producer: you are responsible for building the “AI block” in a process, i.e. the service that can turn e.g. reviews into sentiment insights and the likes.
Even though you most likely will only belong to one of the above two groups, we recommend reading through both the general and technical best practices. It will make it much easier for you to understand the general lifecycle of an AI process.
We’re providing this booklet completely for free and will keep updating it. You can take it as a resource to dive into when thinking about applying LLMs - you certainly will find interesting insights.
At Kern AI, we’re covering toolings designed for the above two user groups: consumers and producers. What does this look like?
- We’re experts in the field of natural language processing, i.e. text-, speech- and document-AI. If you want to understand which use cases might be relevant for your company, we’re happy to help e.g. with workshops.
- For consumers, we offer a process workflow orchestration platform. With this low-code platform, complex and highly customized workflows can be set up in a short time. AI modules for data transformations (e.g. classifications, extractions or conversational AI) are available from organization-specific repositories. The AI modules can be built by internal teams or the Kern AI service team.
- For producers, Kern AI offers toolkits to efficiently create reliable AI models powered by strong training data. Our tools are open-sourced for single-user versions to easily test out (even in commercial use cases), and give control back to developers in the creation process of AI.
If you want to get in contact with us to discuss any of the content described in this booklet, feel free to do so anytime.