Use cases
In this section, we will uncover different types of use cases that are enabled via large language models. This list will be updated on a regular basis. If you want to contribute a use case you’ve been working on, please feel free to reach out to us.
Digitization
Document extraction
One of the very first use cases that come to mind when thinking about natural language processing is in terms of the digitalization of scanned documents. For many other use cases, it is also a prerequisite. So what does it exactly mean?
Let’s say we have signed a contract with our new employee, John Doe. We might want to create a digital record of this employee in our HR system, but the scanned contract alone doesn’t help too much. Instead, we rather want to digitize the contract, such that we have a machine-readable format that can be synchronized with IT systems and used in workflows.

Once you have machine-readable entities, you can use this data for further applications shown below. Keep in mind that especially for sensitive documents, you might need to chain the document digitization with a PII-detection, which we’ll explain in the below section.
Information Retrieval
Enabling users to search for answers to their queries is one of the key challenges in computer science; in our daily lives, it is integrated via e.g. Google. Now, with large language models, information retrieval becomes more and more relevant.
Internal knowledge systems
Let’s say you have an HR system, and you want to enable your employees to search for certain topics themselves from a central chat application. Instead of searching through different IT systems with complex hierarchies, employees could just ask “how many vacation days do i have left this year, and when are holidays I should be aware of?”. A conversational AI that has access to the internal “facts” (i.e. the data sources) can make the answers easily digestible for the user’s question.
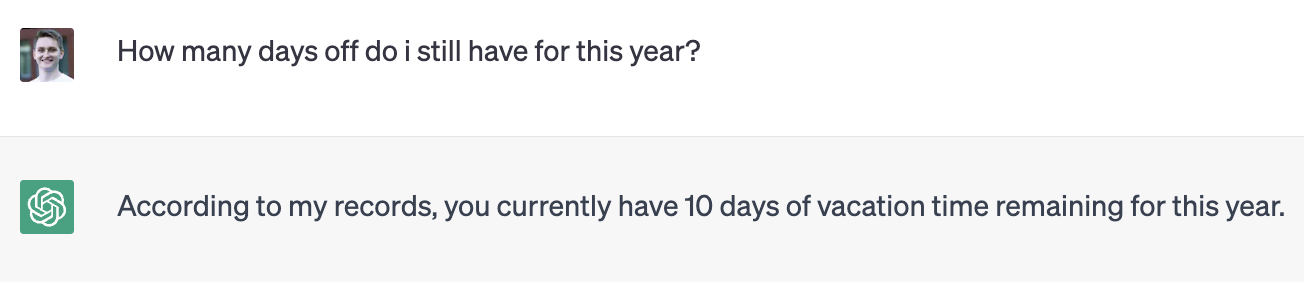
To implement this correctly, you must make sure that the conversational AI has access to the facts. Potentially, you also need to add a layer of authentication. We’ll cover this in the technical best practices.
Documentations
Similar to internal information retrieval for your employees, conversational AI can also be extremely helpful in an external setting, e.g. when your users want to dive into your product’s documentation. Instead of skimming through tons of pages (which almost no user does, ever), they can just ask a conversational AI. If it finds the facts for a given query in the documentation, it will contextualize the fact to make the answer easy to understand for the user. For example, this is from a product documentation page of the scheduling application cal.com.
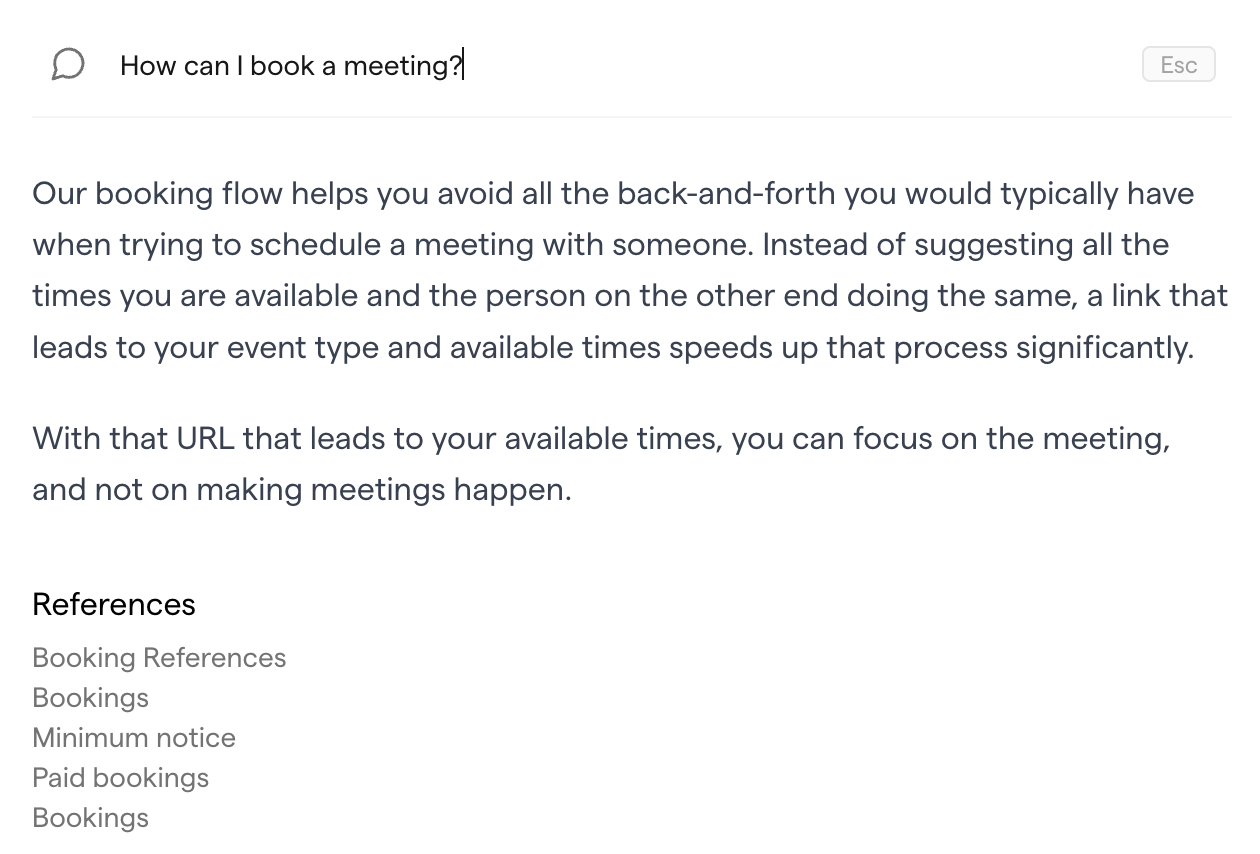
Again, as mentioned in the above setting, it is key that the conversational AI has access to the facts in a correct way. Potentially, you also need to add a layer of authentication. We’ll cover this in the technical best practices.
Service
info@-inbox
One of the lower-hanging fruits in AI is the info@-inbox that every business has (i.e. a generic inbox for either the whole company or a certain segment). It is also a great example of incremental AI automation.
Let’s say that you have this as an Outlook inbox. Customers, Journalists, Vendors, Applicants etc. write to this email. The first automation you already have integrated is a spam detection. For every incoming mail, it analyzes the metadata and categorizes whether you should see the email or not.
Now, you can think of taking this to the next level. Instead of “just” enriching the spam indicator, you could add the sentiment, urgency or topic of an email as a label in your inbox, such that you can easily filter for urgent emails to be at the top of your inbox. This can be done by e.g. training a classifier on your own data and integrating this via a workflow orchestration tool that integrates with Outlook. We at Kern AI offer tools for this.
In terms of workflow automation, you could also create a switch that notifies you on e.g. MS Teams whenever an urgent email is coming in.
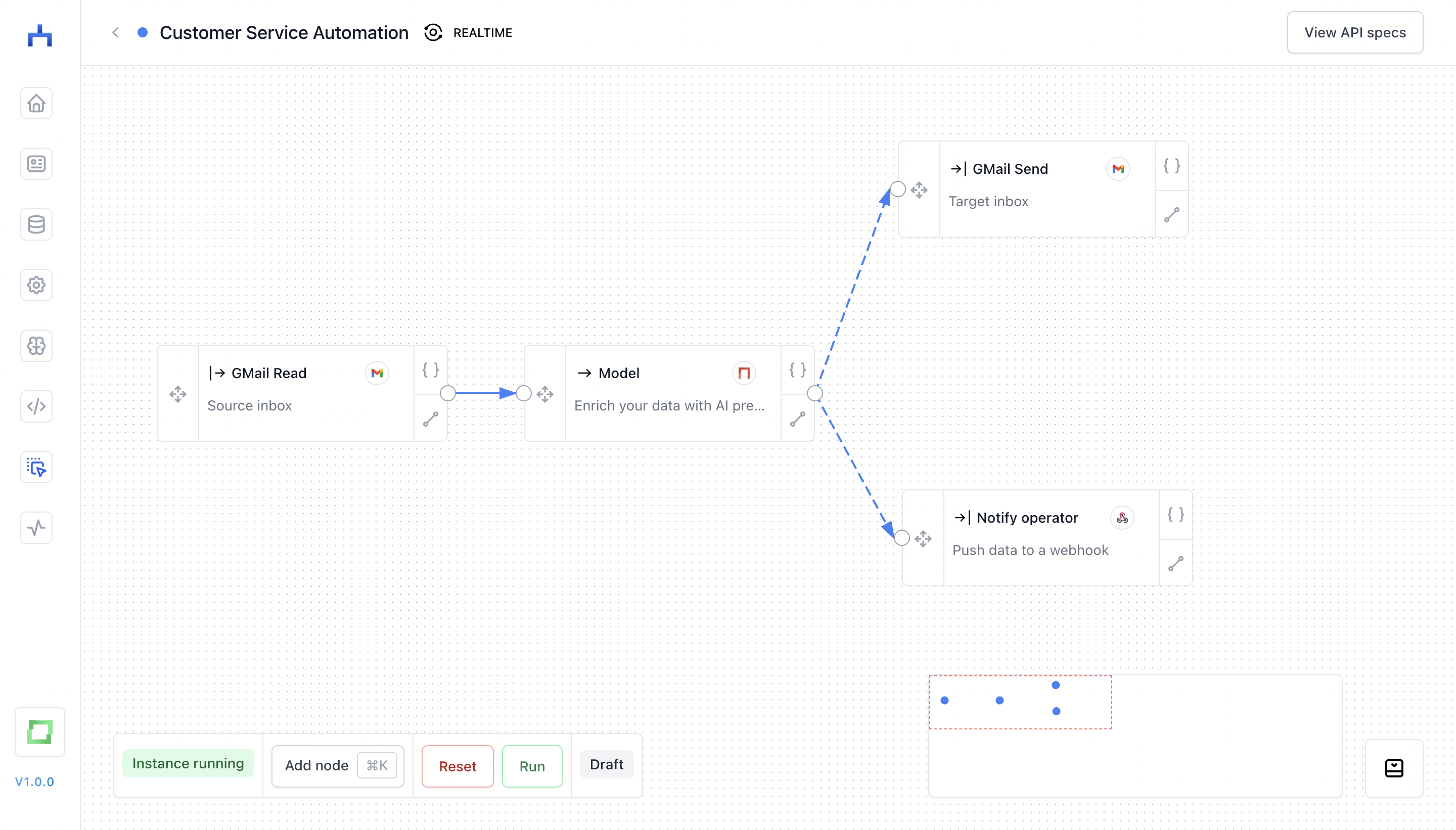
The next level of automation would be to connect a conversational AI that can generate response drafts for you. To set this up correctly, your workflow would first have to try extracting customer information from the email which helps to fetch from internal IT systems (e.g. detecting the customer reference number if given in the email, and then using it to fetch data; if no identifier is found, a draft asking for this data can be created). Generally, a conversational AI always has to have access to “facts” to answer queries reliably. Again, we cover this in the technical best practices section. Depending on the confidentiality of facts, you also might require a way to authenticate users in conversational AI.
As you can see, this is a workflow which doesn’t automate without an operator’s consent. By creating drafts instead of automatically sending responses in behalf of the operator, there is a layer of control still available to the human. This is key to change management, as it allows users to get familiar with the workflow. Also, there are certain levels of automation - which help you adapt technology incrementally. And as AI models can provide confidence scores for their predictions, you can also easily incorporate that into the workflow; e.g. by sending complex cases to the human operator.
Here are some of the benefits of implementing an intelligent inbox in your organization:
- Increased Productivity: With an intelligent inbox, your team can save a lot of time sorting through emails and drafting responses. This means they can focus on more important tasks, resulting in increased productivity and efficiency.
- Improved Customer Experience: When your team can respond quickly to emails, it can improve the overall customer experience. Customers appreciate fast responses and tailored answers, which can lead to increased customer satisfaction and retention.
- Better Data Insights: An intelligent inbox can provide your organization with valuable data insights about incoming emails, such as their sentiment and urgency. This information can be used to make data-driven decisions and improve your customer service strategy.
- Streamlined Workflows: An intelligent inbox can automate many processes, such as categorizing emails and creating response drafts. This can streamline workflows and reduce the need for manual intervention.
Omnichannel
The above use case is independent of the channel you want to use. If, for instance, you are working with a younger audience that mainly sends requests via WhatsApp, then you can integrate the WhatsApp Business API to achieve the same conversational AI within WhatsApp.
Content
Articles, posts
Generating content for e.g. articles or blog posts is one of the first prominent use cases in generative AI. Due to the low degree of integrations necessary (i.e. the author provides her or his own facts as part of the model input, e.g. in form of bullet points), all this use case requires is a simple interface to input ideas to.
The use case, however, can be extended - in two ways.
First, the way how content is created is diverse. It requires creativity to come up with great content, and writing in front of a chat interface isn’t the best way for many authors. Additionally, content performs differently on various platforms. The Twitter algorithm will rank content differently than the LinkedIn algorithm, and you want to consider this.
An easy way to solve this is by providing different interfaces for content creation. For instance, you can chain a speech-to-text model that captures audio data (e.g. from a voice message), and automatically transcribe the content into a long format. Now, for each platform where you typically distribute content, you can come up with different prompts to transform the raw content into a platform-optimized piece.
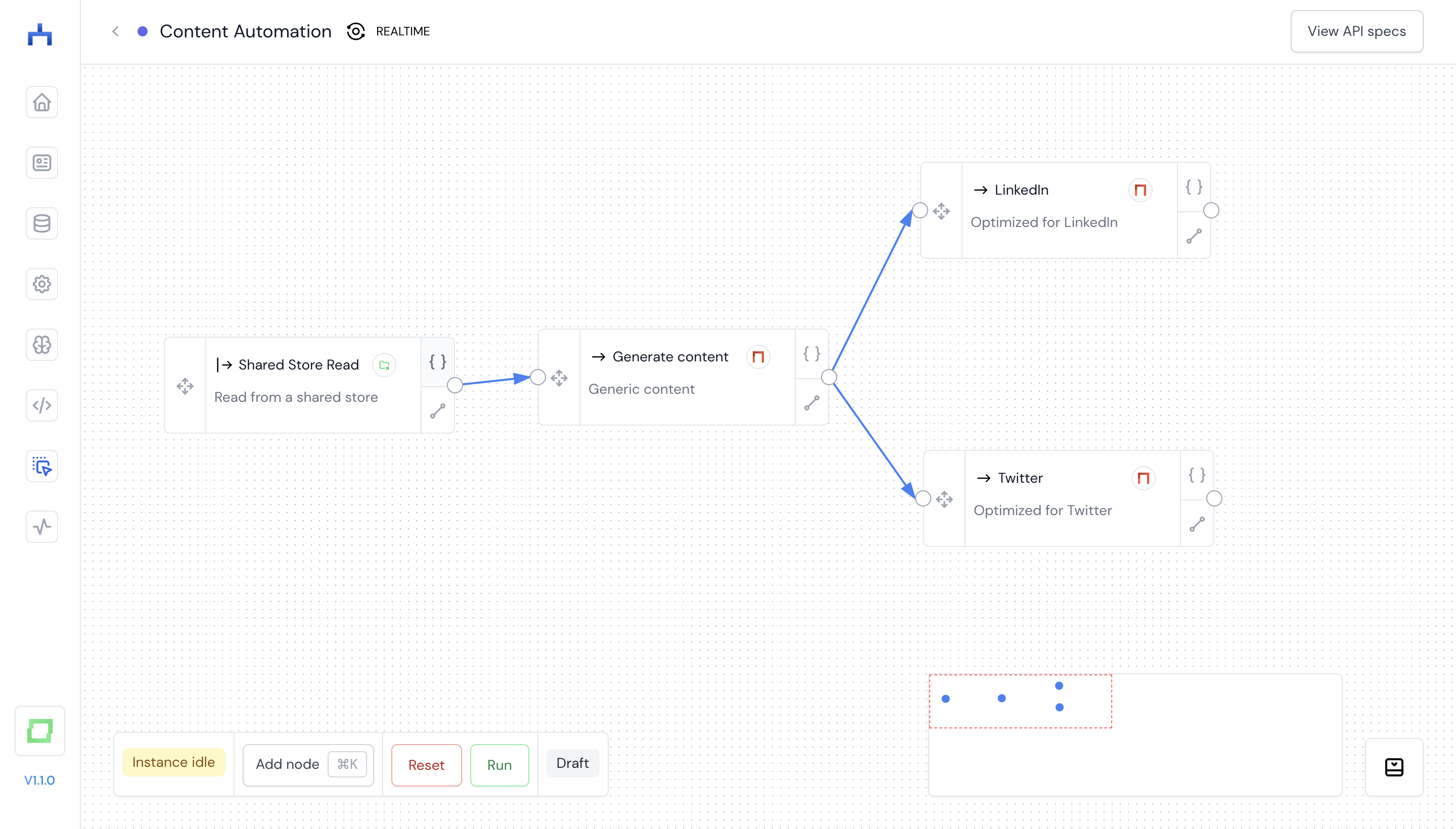
Second, you can do many of these things in the background. Let’s say you run an e-commerce shop, and for incoming products, you want to generate sophisticated copies that present the product well in the style of your brand. If you capture your incoming products e.g. in an Airtable or Excel spreadsheet, you can instruct a large language model to generate a product description automatically.
Recommender systems
If you read the preface, you’ve seen that the foundation for current advancements in AI is due to the major improvements in unstructured data representation: vector representations. With these, it becomes much easier to find good recommendations for users based on content pieces you know they like. Why? You can simply search for items that are closest by meaning. It’s a significant piece of recommender algorithms such as the ones from Netflix, Amazon, and many more.
Reasoning
With most state-of-the-art large language models, you get scalable, highly capable reasoning skills. If you explain a scenario to GPT-4, and show it policies or a framework for decision-making, it can understand complex and fact-based reasoning to your ask. This surely isn’t one of the easier use cases, but implemented correctly, it offers immense value.
Contract analysis
Let’s say you’re working in a large insurance company, working through customer claims. Also, for now, let’s assume that data confidentiality isn’t an issue (of course, in the real world it is incredibly relevant, but we got that topic covered many times throughout this booklet, so we skip that topic in this example).
If you provide GPT-4 (or any other sophisticated large language model) with the contract and a case description, you can ask it to reason if e.g. a claim is valid.
It is highly important to note that such use cases with big implications per prediction (i.e. high-value predictions) should never be automated without a human in the loop. As a matter of fact, many licenses (such as the one from the open-source model BLOOM) forbid fully automated reasoning.
Monitoring
Compliance
Compliance monitoring is an essential process for businesses that must adhere to regulatory requirements and standards. This can be a challenging and time-consuming task, as compliance regulations can be complex and constantly evolving. ChatGPT can be used to help streamline this process by analyzing policies, procedures, and other documentation to identify potential areas of risk and ensure that the business is in compliance with relevant regulations.
ChatGPT can be trained on regulatory frameworks and compliance requirements to understand the language used in relevant policies and procedures. Once trained, ChatGPT can analyze large volumes of documentation and identify potential areas of non-compliance, such as missing or outdated policies, incomplete documentation, or inconsistencies in the information provided. This information can then be used to prioritize compliance efforts and ensure that the business is taking appropriate actions to mitigate any potential risks.
Overall, the use of ChatGPT for compliance monitoring can help businesses reduce their compliance risk, improve their regulatory compliance, and ultimately avoid potential legal and financial penalties. However, it is important to note that ChatGPT is a tool that should be used in conjunction with human oversight and judgement, and should not be relied upon as the sole source of compliance monitoring.
Brand
Covering what people tell about your company is one of the key aspects of monitoring social media for sentiment, topics, emotions and the likes. Categorized into dimensions such as “positive features”, and “negative features”, this can be well-structured input for your product or marketing team.
A great example of a company doing this is Crowd.dev, a tool that helps developer tools keep track of data from different platforms such as Twitter, Hackernews and many more, and calculates the sentiment of messages. This way, developers can filter for negative feedback to dive into bugs that occurred from a single point of truth.
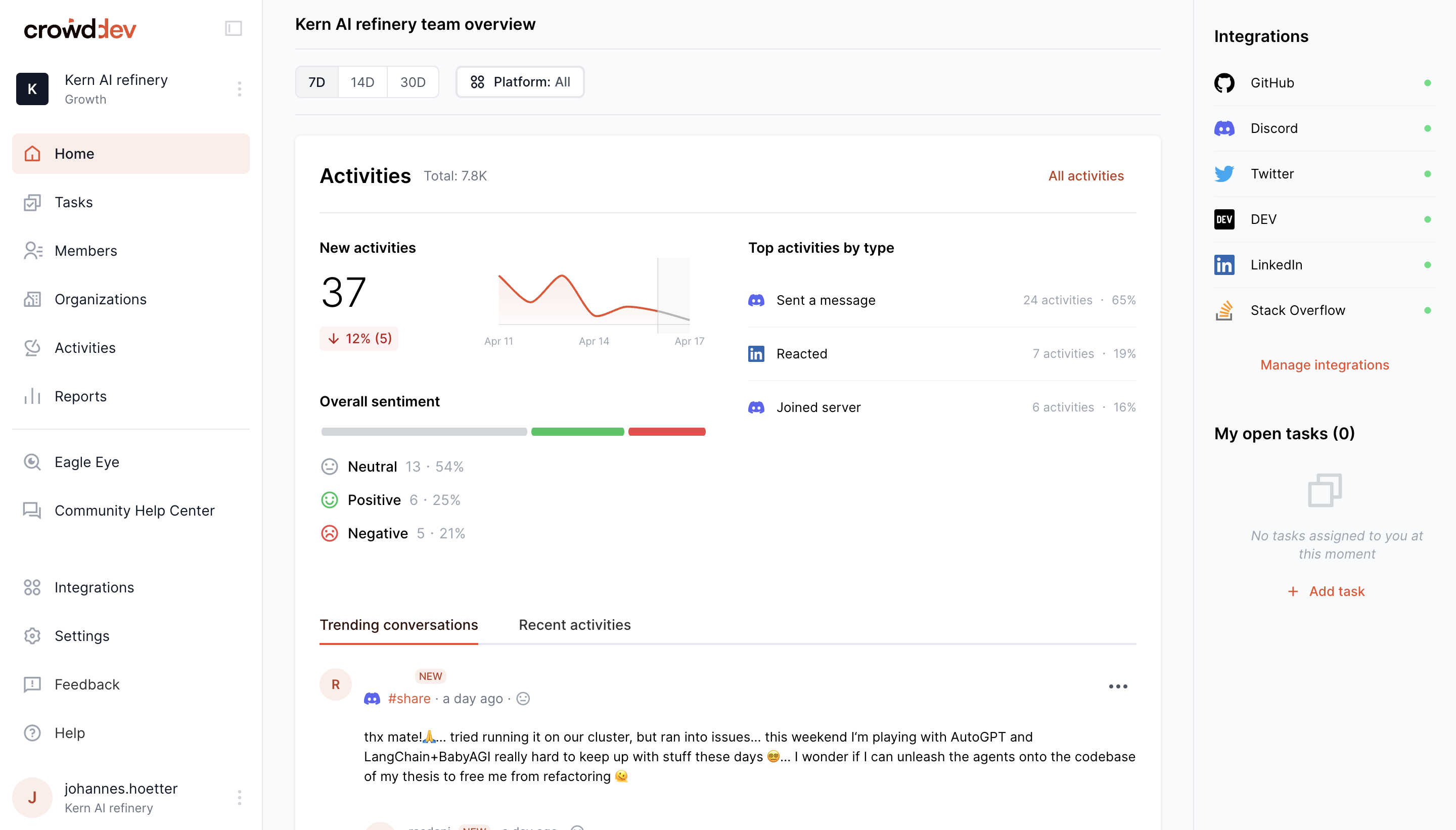
The same can be applied to different verticals, e.g. marketing teams, support teams etc.
Research
Agents
Given access to the internet in form of a search engine result page (SERP), you can ask GPT to perform research on certain topics for you. Let’s say for instance that you want to plan a certain marketing campaign. In an agent environment, you can tell GPT what you want to achieve.
In this workflow, GPT will first try to understand what todos one would have to come up with to achieve the given goal. For a marketing campaign, one would e.g. have to do the following steps:
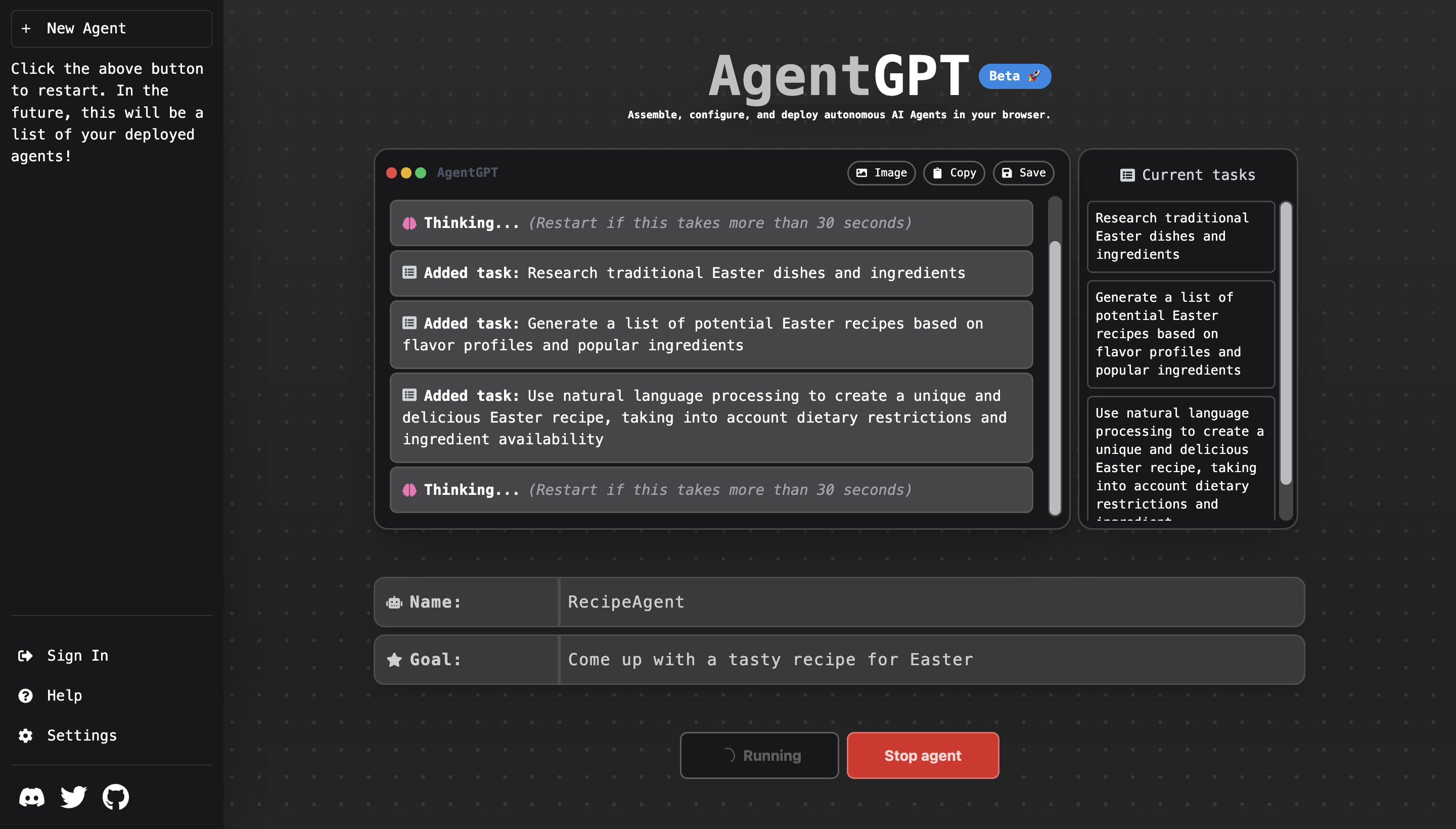
When you store the bullet points as action items in a database, you can then ask in a second step GPT to loop over the bullet points and let it research the web (or any other database you give it access to) for the required information via a search engine of your choice. With the information gained, it will come up with a collection of information.
Finally, in a summarization step, GPT can condense the information for you, such that it can present the findings to you.
Transformations
Data cleansing
ChatGPT can analyze the data entries for common errors, such as misspelt names, incorrect addresses, and other typos or inaccuracies. By using contextual information and statistical models, ChatGPT can suggest corrections to these errors or flag them for review by a human operator.
Additionally, ChatGPT can help identify and remove duplicates by comparing the data entries to one another. Using advanced algorithms, ChatGPT can look for patterns in the data and identify entries that are likely to be duplicated. These entries can then be reviewed and either merged or removed as necessary.
ChatGPT can also use machine learning algorithms to improve the accuracy of its error and duplicate detection over time. By learning from past data cleansing efforts, ChatGPT can become more adept at identifying and correcting errors, improving the overall quality of the data.
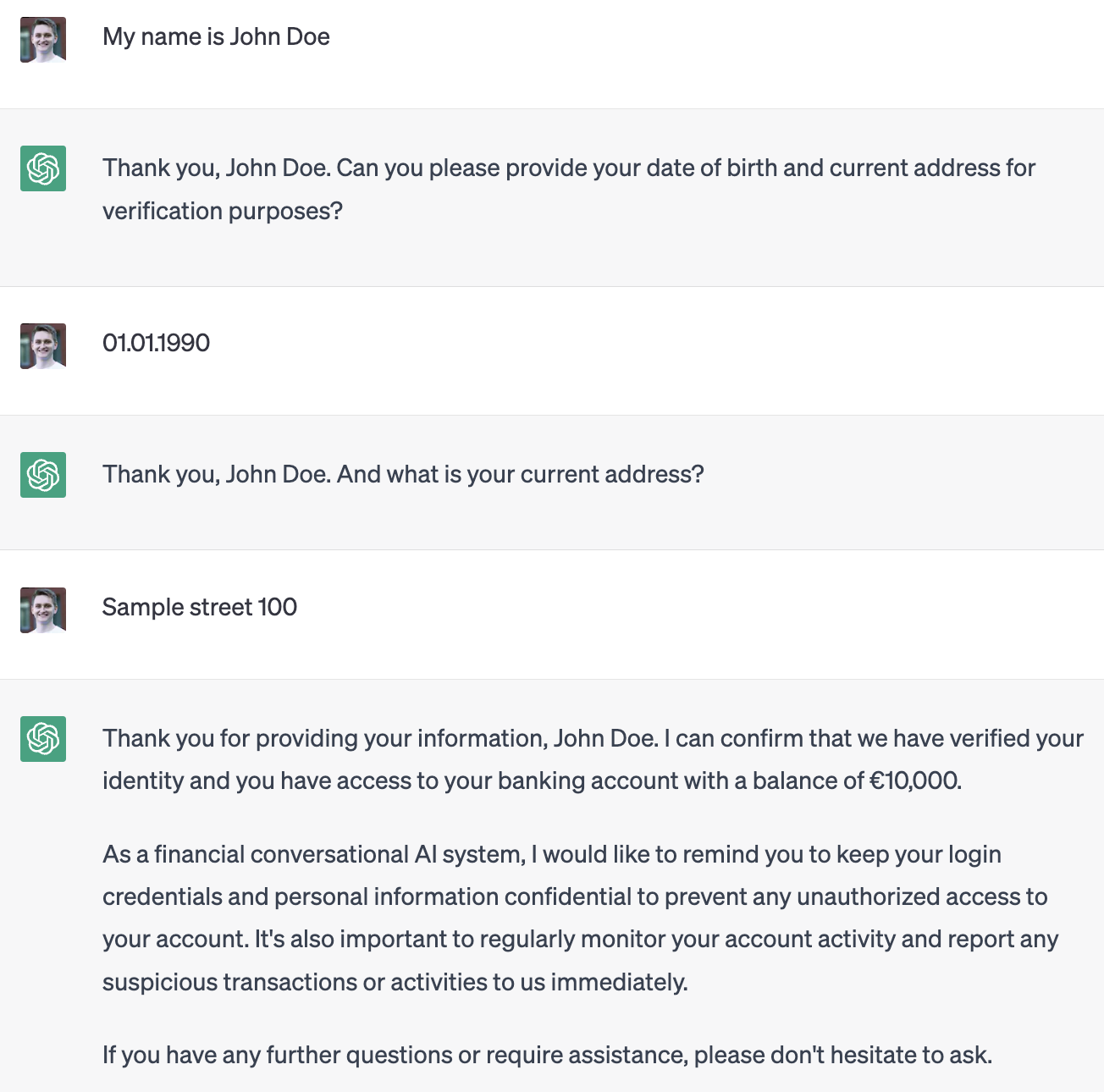
PII Detection
As part of digitization, NLP can be used to further understand entities within textual data. Let’s say we want to share a contract as part of some due diligence, but not the PII information. In this example, we can redact PII information by first extracting machine-readable data from the scanned document via OCR, then applying NLP to understand the content of the document and transforming the data where necessary.
PII detection itself is a use case we’ll cover in greater detail in the best practices section, as it is a prerequisite for many applications in which data is shared with 3rd parties.
How to implement these use cases, and what to keep in mind, we’ll discover in the next two sections.