Technical best practices
How can I make my model better?
Apart from the “science” of writing good prompts, there are ways how you can further improve your AI’s performance. We’ll dive into them now.
Weak supervision
From our experience, the most practical and straightforward approach is to apply weak supervision. The idea is quite simple: combine different algorithms, tailored to your data.
Let’s say that we want to detect the urgency of an incoming customer ticket.
Hi, I accidentally poured coffee over my notebook, have all my data on my machine, and need to give a presentation to the board in 30 minutes. What can I do??
For this case, let’s say that we can generally expect non-confidential requests from the given channel, i.e. data that we can share with OpenAI. Then, of course, we can use GPT to classify the urgency for us, e.g. as follows:
If we collect and label some reference data (e.g. with our open-source refinery), you can benchmark that this GPT might achieve an accuracy of 80% (i.e. on average, in 80 of 100 cases, it will predict the right urgency).
Now, what you can easily do, is build a smaller machine learning model that learns to classify the urgency from the few given labelled examples. This model might achieve an accuracy of 75%. And also, you identify some key terms like “ASAP” or “urgent”, that indicate the urgency with 100% accuracy but aren’t always given. With weak supervision, a model learns how to combine these different votes into one consolidated prediction, which improves your overall accuracy to e.g. 90%.
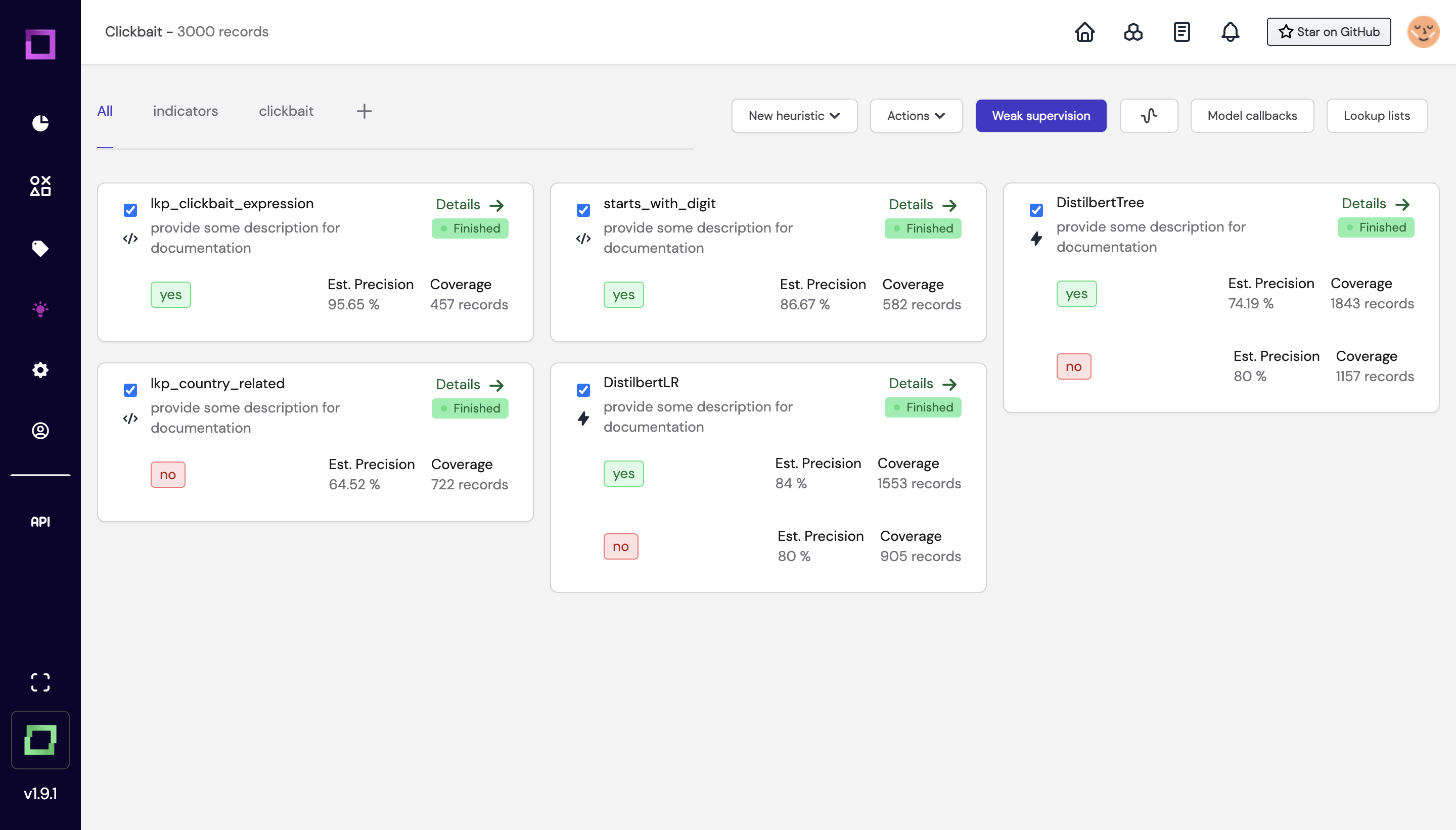
Another great benefit of weak supervision is that you can easily benchmark your different automation. For instance, you can understand the impact of using GPT as an addition to an existing set of rules, or you can compare two different prompts for GPT.
Finetuning generative models
In many cases, you want to fine-tune a generative model to work well in your specific domain. The format to achieve this looks as follows:
| Question | Option 1 | Option 2 | Option 3 | Best Fit |
|---|---|---|---|---|
| What is the capital of France? | Paris | London | New York City | 1 |
| What is the best way to the airport? | Take the train | Drive | Walk | 1 |
| Which phone should I buy? | iPhone | That depends. | Nokia | 2 |
| What should I wear to a wedding? | A suit or formal dress | Jeans and t-shirt | Swimwear | 1 |
| How can I better my programming? | Take a nap | Watch TV all day | Practice regularly | 3 |
In this setting, the chatbot will explore new responses, and gets human feedback (column “Best Fit Answer”) as guidance.
With such datasets, you can fine-tune self-hosted versions of open-source alternatives (again, keep in mind that they are licensed for commercial use!). A fine-tuned model can achieve similar results as GPT, or it can even become more powerful/reliable for the given domain.
Finetuning other models in general
GPT isn’t the only tool available in the machine learning landscape. As mentioned in the above sections, you can build use cases that automate various parts of a chain. Two very common examples include PII (personally identifiable information) and document extraction tasks. You can host them on your premises to ensure that sensitive data doesn’t leave your company, and then interact with GPT only on non-sensitive data.
For these models, you typically require a few hundred to thousand examples of high-quality labels. A great tool to efficiently create such datasets is our open-source project refinery. To create such datasets, you can leverage open-source modules and technologies to help you automate parts of the labelling, and help you pick the training samples which will bring your models the biggest impact. E.g. for PII, you can use our open-source library bricks to search for self-hostable modules that will identify names and organizations in your data with decent off-the-shelf accuracy.
The format of the dataset depends on the task you want to automate. For instance, if you want to binary classify whether a dataset contains PII, it could look like this:
| Text | Contains PII? |
|---|---|
| My name is John Smith. | True |
| I live at 123 Main St. | True |
| You can contact me at [email protected]. | True |
| My favorite color is blue. | False |
| I was born on January 1, 1990. | True |
| My social security number is 123-45-6789. | True |
| I work at Acme Corporation. | False |
| My phone number is (555) 123-4567. | True |
| My credit card number is 1234-5678-9012-3456. | True |
| I graduated from Harvard University in 2012. | False |
On the other hand, if you want to identify where the PII data is, so you can potentially exchange it with anonymized data, it looks roughly like this:
| Text | PII Type | Start Position | End Position |
|---|---|---|---|
| My name is John Smith and my email is [email protected]. | Name, Email | 11 | 48 |
| I live at 123 Main St, Anytown, USA. | Address | 10 | 27 |
| My phone number is (555) 123-4567. | Phone Number | 19 | 32 |
| My social security number is 123-45-6789. | Social Security Number | 27 | 39 |
| My credit card number is 1234-5678-9012-3456. | Credit Card Number | 24 | 43 |
| I was born on January 1, 1990. | Date of Birth | 14 | 28 |
| My passport number is ABC123456. | Passport Number | 22 | 30 |
| My driver's license number is A123-456-789-0. | Driver's License Number | 26 | 43 |
| I work at Acme Corporation. | None | - | - |
| My favourite colour is blue. | None | - | - |
And then again, if you want to detect elements inside of a PDF scanned document, you rather work via bounding boxes, e.g. the layout data of the document. For PII redaction, it could look like this:
| PDF File | Page Number | Object Type | Bounding Box | Contains PII |
|---|---|---|---|---|
| Document1.pdf | 1 | Text | [x1, y1, x2, y2] | No |
| Document1.pdf | 1 | Text | [x3, y3, x4, y4] | Yes |
| Document1.pdf | 1 | Image | [x5, y5, x6, y6] | No |
| Document1.pdf | 2 | Text | [x7, y7, x8, y8] | No |
| Document1.pdf | 2 | Text | [x9, y9, x10, y10] | Yes |
| Document2.pdf | 1 | Table | [x11, y11, x12, y12] | No |
| Document2.pdf | 1 | Text | [x13, y13, x14, y14] | No |
At Kern AI, we are happy to help you create and maintain such datasets with low internal effort.
How to leverage GPT for prototyping and scaling models
Apart from GPT being a strong tool during runtime (i.e. in production), it is also an incredibly powerful mechanism to create training data for models. Let’s say you want to build an in-house chatbot for HR questions. GPT can be incredibly helpful for this.
Creating synthetic data
First, you can ask GPT to act as a user of your chatbot. Following the above mentioned prompt engineering framework (giving context and instructions for how the data should be displayed), you can easily come up with a way to let GPT generate example questions for you:
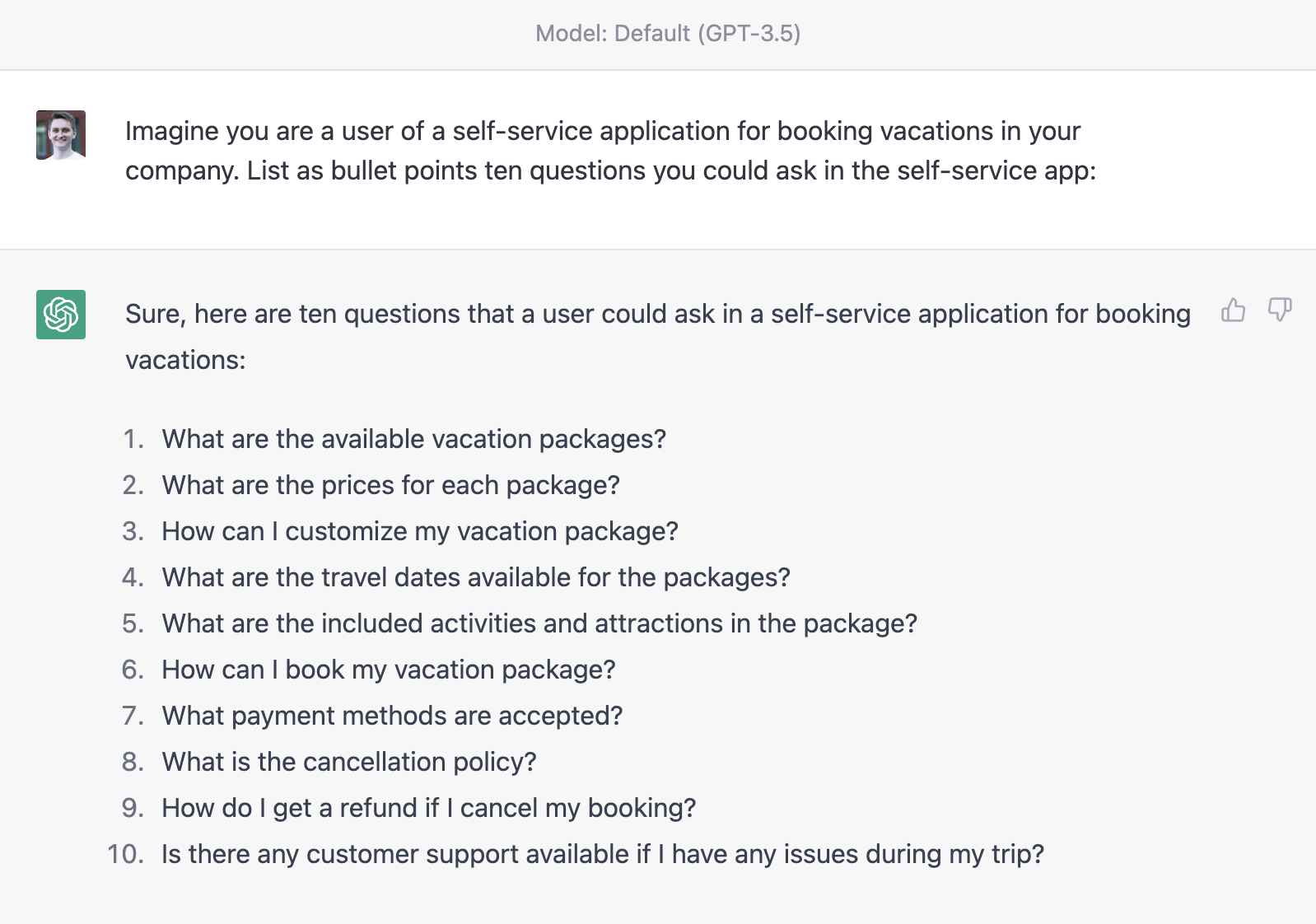
Quickly skim through the dataset to check if it makes sense to you. Refine this with e.g. 10 examples until you are happy with the quality of the questions, and then scale it up to e.g. 1,000. These are 1,000 samples that you can then use train a self-hosted chatbot, without having to call ChatGPT. If you require these samples to be labeled, you can again apply the logic of the above mentioned weak supervision strategy.
As long as your prompt is not containing sensitive information, this approach is safe.
Expanding data
Further, you can use GPT to grow your dataset for self-hosted models. Let’s say you already have 100 manually collected chat examples. If required, anonymize them by hand, and send them to GPT with the ask to create more of such examples.
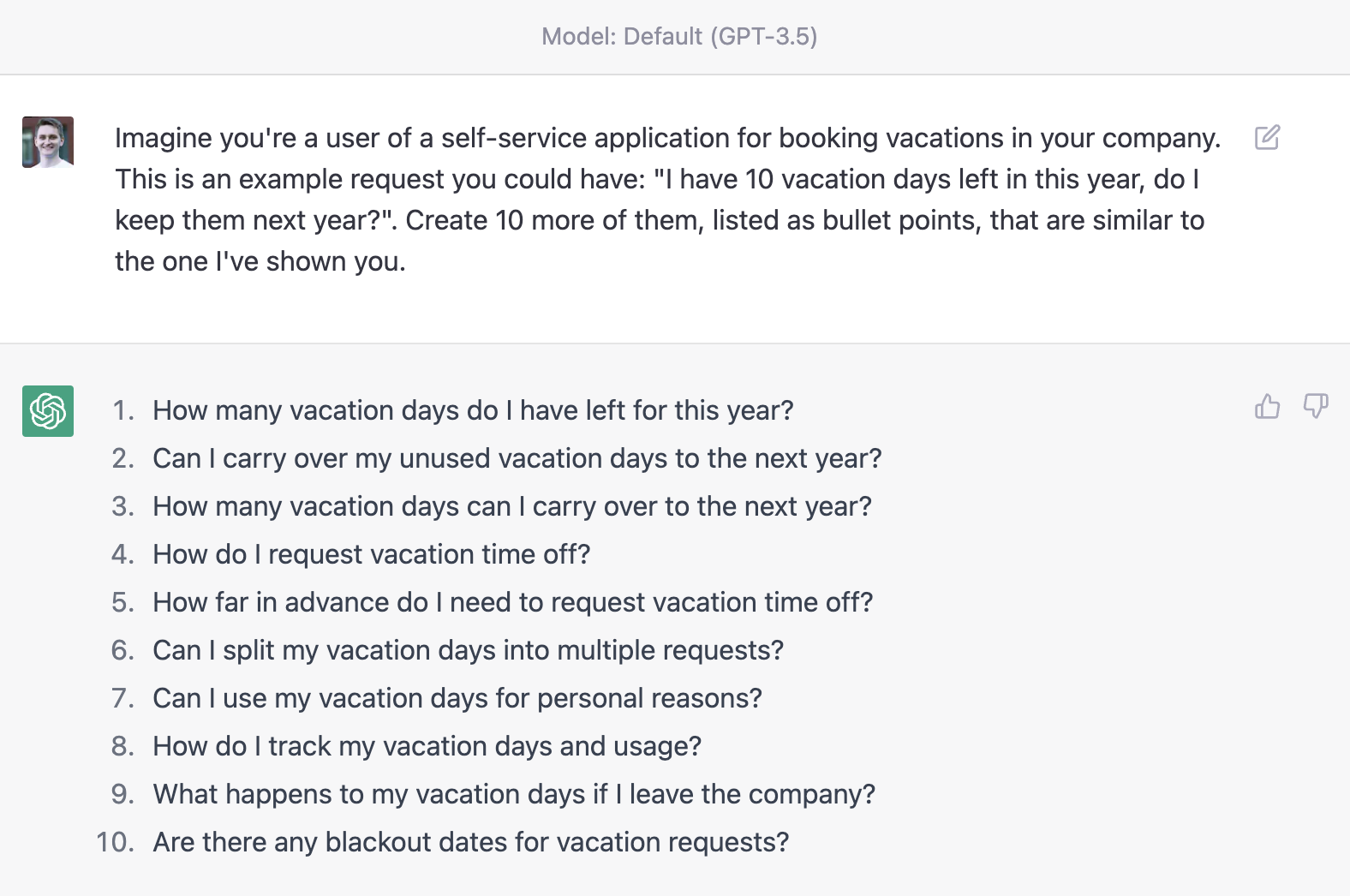
With this approach, for existing models, you can augment the training data. This makes your model more reliable and precise, i.e. allows you to go e.g. from a 90% accuracy to 95% accuracy.
GPT as a teacher for smaller models
One way GPT can be used to distil knowledge into self-trained models is by labelling data. This is similar to how a teacher shows a student how to solve certain tasks, and the more examples the teacher demonstrates to the student, the better the student gets. By using GPT to generate new labelled data you can effectively increase the size of your training set and improve model performance.
We cover this in greater detail in the weak supervision section.
Role of data quality
High-quality training data is of paramount importance in NLP. The accuracy and effectiveness of NLP models depend heavily on the quality of the data that they are trained on. The better the quality of the training data, the better the model's ability to understand and process natural language. It is therefore crucial to minimize the number of labelling mistakes in the training dataset as much as possible. Even a small percentage of mislabeled data can significantly reduce the accuracy of an NLP model. Therefore, data quality checks, data cleaning, and data validation must be performed regularly to ensure that the training data is of the highest possible quality. By doing so, NLP models can be trained more effectively and produce more accurate results, which can have a significant impact on many areas such as customer service, virtual assistants, and machine translation.
Cut out GPT
Starting an NLP use case by using GPT as the inference model can be a good way to quickly get up and running with your project. By using GPT as the initial inference model, you can quickly validate your use case and get a sense of the results you can expect. As you collect more data, you can start building your own classifier using the newly gained training data. Once you have collected sufficient data, for example, 10,000 samples with GPT's predictions as the labels, you can use this data to train your own classifier model. This approach can be beneficial as it allows you to leverage the power of GPT as a starting point and then refine your model based on your specific use case and requirements. By doing so, you can create a more tailored model that is better suited to your specific use case, providing more accurate results and better performance.
How to benchmark different large language models
How GPT responds to your questions is highly dependent on how you formulate a question. Due to this characteristic, you can set up multiple experiments with different prompts, in this toy example as follows:
If you want to find out which prompt works best for your use case, once again, you should look into refinery. With refinery, you can setup both prompts, call GPT, and see which prompt performs best directly in your labeling environment.
How to generally benchmark NLP
Benchmarking is a crucial step in evaluating the performance of NLP models. It is the process of measuring the accuracy and efficiency of the model against a set of predefined metrics. The following are some ways to benchmark different NLP tasks:
Classifications & extractions
To benchmark classification and extraction models, you can use metrics such as accuracy, precision, recall, and F1 score. Accuracy measures the percentage of correctly classified instances, while precision and recall measure the proportion of true positives and true negatives. F1 score is the harmonic mean of precision and recall and provides a balanced view of the model's performance. You can also use confusion matrices to visualize the model's performance on different classes.
Generations
Benchmarking in generative AI is still highly challenging. However, you can use metrics such as perplexity, BLEU score, and ROUGE score to evaluate the quality of the generated text. Perplexity measures how well the model predicts the next word in the sequence, while BLEU score measures the similarity between the generated text and the reference text. ROUGE score measures the overlap between the generated text and the reference text. You can also use human evaluations to assess the quality of the generated text.
Rankings & search
To benchmark ranking and search models, you can use metrics such as precision at k, mean average precision, and normalized discounted cumulative gain. Precision at k measures the proportion of relevant results returned by the model in the top k results. Mean average precision measures the average precision across all relevant documents. Normalized discounted cumulative gain measures the quality of the ranking by taking into account the relevance of the documents returned by the model. You can also use other evaluation metrics such as reciprocal rank and expected reciprocal rank to assess the model's performance on different types of queries.
Foundation models
Some people prefer to use the term "foundation model" (FM) instead of LLM/Generative AI for several reasons. FMs can be utilized for any type of AI application, not just generative use cases. For instance in sentiment analysis. Also, it's worth noting that while FMs are powerful bases, they are often not enough for production in real-world use cases. Additional work is still required, such as fine-tuning on labelled, domain- and task-specific data, to get the best results. As described in the section on general best practices, you can use LLMs, but should remember that they often are not the only part of a system.